Large language models (LLMs), with their comprehensive solutions and expanded capabilities, have revolutionized the field of natural language processing (NLP). These models, trained on enormous text datasets using transformer-based architectures such as BERT, GPT, or T5, may perform a variety of tasks such as text production, translation, summarization, and question answering.
However, while LLMs are effective tools, they are frequently incompatible with specific activities or domains due to their generalized training on broad data corpora.
Through the LLM fine-tuning process, users can modify pre-trained LLMs to focus on specific downstream tasks. They can use techniques such as gradient descent optimization and backpropagation on labeled data. You can increase a model’s performance on a given task while retaining its across-the-board language knowledge by fine-tuning it on a carefully curated small dataset of task-specific data.
For instance, a Google study discovered that a pre-trained LLM’s accuracy increased by 10% when it was fine-tuned for sentiment analysis. In this blog, we examine what are fine-tuned LLMs and how it can lead to more accurate and context-specific outcomes, lower training costs, and a significant improvement in model performance.
What are Fine-tuned LLMs?
LLMs are a subset of foundation models, which are general-purpose machine learning models capable of solving a wide range of tasks using large-scale neural networks. Fine-tuned LLMs are models that have undergone additional training using task-specific objectives, which increases their usefulness for particular tasks and industries, like software development.
Despite their exceptional versatility, LLMs may perform ineffectively on highly specific tasks requiring domain expertise since they are trained on linguistic data and possess knowledge of syntax, semantics, and context but lack focus on niche domains.
For various applications, the base LLM can be fine-tuned with smaller labeled datasets, focusing on specific domains. Fine-tuning utilizes supervised learning, a technique where models are trained using gradient-based optimization algorithms such as AdamW to minimize task-specific loss functions like cross-entropy or mean squared error. These prompt-response pairs help the model understand relationships between inputs and outputs, allowing it to generalize on previously unseen data within the domain.
How Does the Data Labeling Process Help in Fine Tuning? 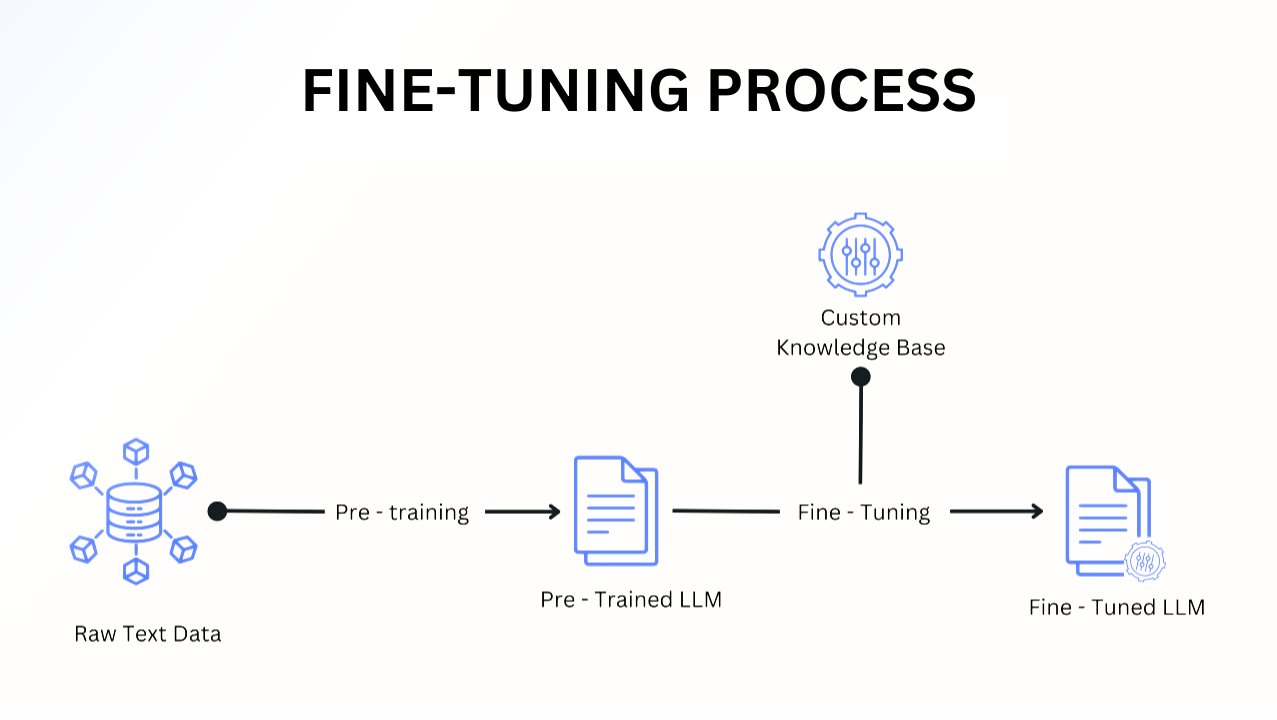 The annotations necessary for fine-tuning are instruction-anticipated response pairs, with each input corresponding to an expected output. While picking and categorizing data in a data labeling process may appear to be a simple operation, various factors contribute to its complexity.
The annotations necessary for fine-tuning are instruction-anticipated response pairs, with each input corresponding to an expected output. While picking and categorizing data in a data labeling process may appear to be a simple operation, various factors contribute to its complexity.
- Data Collection: The data should be clearly defined; it must also be relevant while covering a wide variety of potential interactions. This includes cases with a high level of uncertainty, such as using sentiment analysis on sarcastic product evaluations or domain-specific jargon.
- Preprocessing: After data collection, it is often cleaned and preprocessed to reduce noise and inconsistencies. Tasks include tokenization, normalization, lemmatization, and vectorization using tools like spaCy or NLTK. Outliers and duplicate records are eliminated, and imputation is used to replace missing values.
- Annotation Tools: Human annotators, aided by tools like Label Studio or Prodigy, mark the data appropriately. Many labeling platforms provide AI-assisted pre-labeling, an autonomous data labeling process using algorithms like BERT-based classifiers to detect relevant words and phrases.
- Validation and Quality Assurance (QA): After the data has been labeled, the labels are validated using inter-annotator agreement (IAA) metrics such as Cohen’s Kappa or Fleiss’ Kappa, which ensure consistency. Automated technologies like Active Learning pipelines can also validate data and identify discrepancies. The labeled data is then encoded into vector formats using embeddings like word2vec, GloVe, or contextual embeddings like BERT.
Techniques for NLP and LLM Data Labeling
The annotation process becomes difficult because text data might be subjective. A set of standard practices for data labeling can help with many of these issues. Make sure you fully comprehend the issue you are trying to solve before you begin. You will be more capable of producing a dataset that includes all edge situations and variants if you have more information.
When selecting annotators, your vetting procedure should be as comprehensive. Data labeling techniques involve a process that requires a great deal of attention to detail, reasoning, and insight. These strategies are quite helpful to the annotating process.
The following are some techniques for NLP and LLM data labeling you can take to guarantee a successful fine-tuning procedure.
1. Start with a Small Model
Starting with a smaller model makes fine-tuning easier. Models like DistilBERT or ALBERT enable quicker testing and iteration because they use less memory and processing power. This strategy is especially useful when resources are limited. Once the process has been refined on a smaller scale, the lessons learned can be used to fine-tune larger models.
2. Experiment with Various Data Formats
Experimenting with different data types can greatly improve the effectiveness of fine-tuning. Models can learn to handle a greater range of real-world events by accepting a variety of input formats, including structured data (e.g., CSV files), unstructured text (e.g., logs), images, or even multi-modal data. This diversity ensures robust embeddings and contextualized outputs.
3. Ensure That the Dataset is High-Quality
To ensure that the model learns the appropriate patterns and nuances, the dataset should be representative of the job and domain. Techniques like stratified sampling, adversarial testing, and domain-driven dataset augmentation help ensure robustness. High-quality data reduces noise and mistakes, allowing the model to produce more precise and consistent results.
4. Use Hyperparameters to Optimize Performance
Hyperparameter tuning is critical for improving the performance of finely tuned models. Key parameters such as learning rate, batch size, dropout rates, gradient clipping thresholds, and epoch count must be adjusted to strike a balance between learning efficiency and overfitting prevention. Tools like Optuna or Ray Tune can automate hyperparameter optimization.
Best LLM Fine-Tuning Methods
There are various ways and approaches for fine-tuning model parameters to meet a specific demand. These LLM fine-tuning methods can be broadly divided into two groups: supervised fine-tuning and reinforcement learning from human feedback (RLHF).
1. Supervised Fine-Tuning
The model is trained using this method on a task-specific labeled dataset, with each input data point assigned a right answer or label. The model learns to change its parameters to predict these labels appropriately. This procedure directs the model to adapt its prior knowledge, achieved from pre-training on a huge dataset, to the specific job at hand.
The most widely used supervised fine-tuning approaches are:
- Basic hyperparameter tuning: Basic hyperparameter tuning is a simple method in which you manually tweak model hyperparameters such as the learning rate, batch size, and number of epochs until you obtain the desired performance.
- Transfer Learning: Transfer learning is an effective method that works especially well when there is a lack of task-specific data. This approach begins with a model that has been pre-trained on a big, broad dataset. The model is then fine-tuned using task-specific data, enabling it to apply its previous expertise to the current task.
- Multi-task learning: Multi-task learning involves fine-tuning the model on several related tasks at the same time. The goal is to increase the model’s performance by using commonalities and differences between these tasks. Learning to do many tasks at the same time allows the model to gain a more robust and generalized grasp of the input.
- Few-shot learning: Few-shot learning allows a model to learn a new task with minimal task-specific information. To learn a new task, this technique gives the model a few instances or “shots” during inference time. By giving context and examples right in the prompt, few-shot learning aims to shape the model’s predictions.
- Task-specific fine-tuning: This strategy enables the model to tailor its parameters to the complexities and requirements of the target task, improving its performance and relevance to the relevant domain. Task-specific fine-tuning is especially useful when you wish to optimize the model’s performance for a single and well-defined task.
2. Reinforcement Learning From Human Feedback (RLHF)
Reinforcement learning from human feedback (RLHF) uses interactions with human feedback to train language models. RLHF helps to continuously improve language models so they generate more accurate and contextually relevant responses by integrating human feedback into the learning process.
The most commonly used RLHF procedures are:
- Reward modeling: In this approach, the model produces a number of potential actions or outputs, and human assessors provide a quality rating for each of these outputs. The model then learns to anticipate these human-provided rewards and tailors its behavior to maximize the projected benefits.
- Proximal policy optimization (PPO): It is an iterative approach that adjusts the language model’s policy to maximize the predicted reward. PPO’s main goal is to provide improvements to the policy without making significant modifications to the previous one.
- Comparative ranking: It relates to reward modeling. In this approach, the model creates various outputs or actions, which are then ranked by human evaluators based on their quality or suitability. The model then learns to modify its behavior in order to create outputs that are rated higher by the evaluators.
- Preference learning: It is often known as reinforcement learning using preference feedback. The model produces a number of outputs in this method, and human evaluators select their preferred output pairs. The model then learns to adapt its behavior to provide results that are consistent with the preferences of the human evaluators.
- Parameter-efficient fine-tuning: Parameter-efficient fine-tuning (PEFT) is a strategy that improves pre-trained LLM performance on specified downstream tasks while reducing the amount of trainable parameters. PEFT selectively adjusts only a fraction of the LLM’s parameters, usually by adding new layers or changing the present ones in a task-specific way.
Evaluating Fine-Tuned LLM Performance
While fine-tuning can enormously improve the performance of LLMs for specific tasks, evaluating the effectiveness of the fine-tuning process is vital to make sure that the model performs as expected. Without proper evaluation metrics and validation techniques, models might overfit or fail to generalize on unseen data. This section delivers an overview of key evaluation methods and tools for assessing fine-tuned LLM performance.
Key Evaluation Metrics for Fine-Tuned LLMs
Here are some key metrics that can be monitored to measure the performance of fine-tuned performance:
1. Task-Specific Metrics:
- Accuracy: Useful for classification tasks such as sentiment analysis or intent recognition.
- F1 Score: Balances precision and recall, particularly for imbalanced datasets.
- BLEU/ROUGE Scores: Evaluate the quality of generated text in summarization or translation tasks.
- Perplexity: Measures how well the model predicts sequences of words, useful in language modeling tasks.
2. Generalization Metrics:
- Out-of-Sample Accuracy: Assesses performance on unseen data to measure generalization.
- Cross-Domain Evaluation: Validates the model’s adaptability to new but related domains.
3. Robustness Metrics:
- Adversarial Accuracy: Tests how the model performs against adversarial examples.
- Error Analysis: Identifies failure cases using techniques such as SHAP (SHapley Additive exPlanations) for interpretability.
Validation Techniques
Here are validation techniques that one can use:
- Cross-Validation: Splits the dataset into training and validation sets multiple times to ensure consistency across splits. Techniques like k-fold cross-validation can help identify model robustness.
- A/B Testing: Compares the fine-tuned model’s outputs with the base model or alternative models in real-world applications to measure improvements.
- Human Evaluation: In tasks like text summarization or chatbot responses, human reviewers assess the model’s outputs for relevance, coherence, fluency, and correctness.
- Explainability and Interpretability: Tools like LIME (Local Interpretable Model-Agnostic Explanations) and SHAP can provide insights into the model’s predictions, helping validate if the model is making decisions for the right reasons.
Here are the list of tools that can be used for validation:
- Hugging Face Evaluate: A library for implementing standard NLP evaluation metrics easily.
- OpenAI’s API Metrics: Tracks and benchmarks performance for tasks like completions and embeddings.
- TensorBoard: Monitors fine-tuning progress through visualizations like loss curves, accuracy metrics, and gradients.
Fine-tuned LLMs often face concept drift in dynamic domains where data distributions evolve over time. Setting up monitoring pipelines using tools like MLflow or Prometheus can track performance and retrain the model when necessary.
Bottom Line
Fine-tuned LLMs have already demonstrated remarkable promise, with tools and platforms for LLM data labeling such as MedLM and CoCounsel employed professionally in specialized applications on a daily basis. An LLM tailored to a certain domain can be a very powerful and valuable tool, but only if it is fine-tuned using relevant and reliable training data.
Automated solutions, such as employing an LLM for data labeling, can speed up the process, but creating and annotating an excellent training dataset demands human expertise.
Hiring remote LLM fine-tuning experts can help you improve the accuracy and efficacy of your data labeling process. However, hiring a remote LLM expert can be demanding and time-consuming. Hyqoo can help you streamline this process with AI.
Our AI Talent Cloud analyzes your specific requirements and preferences to recommend the most qualified professionals for your open positions. Explore our website to connect with Hyqoo specialists and effortlessly onboard remote LLM experts.
FAQs
1. What do you mean by data labeling in LLM?
A key step in training large language models (LLMs) is data labeling, which involves annotating the training data the model uses to gain context. To help the model train more efficiently, the data is labeled with information like categories, relationships, or sentiment.
2. What is the process for labeling data in machine learning?
Following the collection of the training data, the data labeling procedure starts. Using a tool such as SuperAnnotate or Supervisely, human annotators label data points. To make things more efficient, a lot of technologies now allow automated pre-labeling. A QA procedure and a thorough set of guidelines that are updated on a regular basis should be put in place to guarantee quality.
3. How should data be annotated for an LLM?
Teams of individuals often produce and review the annotations in the LLM data labeling and annotation process. Although human participation is necessary to assure accuracy, AI-assisted prelabeling can generate labels and annotations more efficiently. Data labeling software, such Label Studio or Labelbox, is commonly used for data labeling.












